Text Classification with Noisy Labels#
Consider Using Datalab
If you are interested in detecting a wide variety of issues in your text dataset, check out the Datalab text tutorial. Datalab can detect many other types of data issues beyond label issues, whereas CleanLearning is a convenience method to handle noisy labels with sklearn-compatible classification models.
In this 5-minute quickstart tutorial, we use cleanlab to find potential label errors in an intent classification dataset composed of (text) customer service requests at an online bank. We consider a subset of the Banking77-OOS Dataset containing 1,000 customer service requests which can be classified into 10 categories corresponding to the intent of the request. cleanlab will shortlist examples that confuse our ML model the most; many of which are potential
label errors, out-of-scope examples, or otherwise ambiguous examples. cleanlab’s CleanLearning class automatically detects and filters out such badly labeled data, in order to train a more robust version of any Machine Learning model. No change to your existing modeling code is required!
Overview of what we’ll do in this tutorial:
Define a ML model that can be trained on our dataset (here we use Logistic Regression applied to text embeddings from a pretrained Transformer network, you can use any text classifier model).
Use
CleanLearningto wrap this ML model and compute out-of-sample predicted class probabilites, which allow us to identify potential label errors in the dataset.Train a more robust version of the same ML model after dropping the detected label errors using
CleanLearning.
Quickstart
Already have an sklearn compatible model, data and given labels? Run the code below to train your model and get label issues using CleanLearning.
You can subsequently use the same CleanLearning object to train a more robust model (only trained on the clean data) by calling the .fit() method and passing in the label_issues found earlier.
from cleanlab.classification import CleanLearning
cl = CleanLearning(model)
label_issues = cl.find_label_issues(train_data, labels) # identify mislabeled examples
cl.fit(train_data, labels, label_issues=label_issues)
preds = cl.predict(test_data) # predictions from a version of your model
# trained on auto-cleaned data
Is your model/data not compatible with CleanLearning? You can instead run cross-validation on your model to get out-of-sample pred_probs. Then run the code below to get label issue indices ranked by their inferred severity.
from cleanlab.filter import find_label_issues
ranked_label_issues = find_label_issues(
labels,
pred_probs,
return_indices_ranked_by="self_confidence",
)
1. Install required dependencies#
You can use pip to install all packages required for this tutorial as follows:
!pip install sentence-transformers
!pip install cleanlab
# Make sure to install the version corresponding to this tutorial
# E.g. if viewing master branch documentation:
# !pip install git+https://github.com/cleanlab/cleanlab.git
[2]:
import re
import string
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split, cross_val_predict
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
from sentence_transformers import SentenceTransformer
from cleanlab.classification import CleanLearning
2. Load and format the text dataset#
[4]:
data = pd.read_csv("https://s.cleanlab.ai/banking-intent-classification.csv")
data.head()
[4]:
| text | label | |
|---|---|---|
| 0 | i accidentally made a payment to a wrong account. what should i do? | cancel_transfer |
| 1 | i no longer want to transfer funds, can we cancel that transaction? | cancel_transfer |
| 2 | cancel my transfer, please. | cancel_transfer |
| 3 | i want to revert this mornings transaction. | cancel_transfer |
| 4 | i just realised i made the wrong payment yesterday. can you please change it to the right account? it's my rent payment and really really needs to be in the right account by tomorrow | cancel_transfer |
[5]:
raw_texts, raw_labels = data["text"].values, data["label"].values
raw_train_texts, raw_test_texts, raw_train_labels, raw_test_labels = train_test_split(raw_texts, raw_labels, test_size=0.1)
[6]:
num_classes = len(set(raw_train_labels))
print(f"This dataset has {num_classes} classes.")
print(f"Classes: {set(raw_train_labels)}")
This dataset has 10 classes.
Classes: {'cancel_transfer', 'lost_or_stolen_phone', 'change_pin', 'visa_or_mastercard', 'supported_cards_and_currencies', 'beneficiary_not_allowed', 'card_about_to_expire', 'card_payment_fee_charged', 'apple_pay_or_google_pay', 'getting_spare_card'}
Let’s print the first example in the train set.
[7]:
i = 0
print(f"Example Label: {raw_train_labels[i]}")
print(f"Example Text: {raw_train_texts[i]}")
Example Label: getting_spare_card
Example Text: can i have another card in addition to my first one?
The data is stored as two numpy arrays for each the train and test set:
raw_train_textsandraw_test_textsstore the customer service requests utterances in text formatraw_train_labelsandraw_test_labelsstore the intent categories (labels) for each example
First, we need to perform label enconding on the labels, cleanlab’s functions require the labels for each example to be an interger integer in 0, 1, …, num_classes - 1. We will use sklearn’s LabelEncoder to encode our labels.
[8]:
encoder = LabelEncoder()
encoder.fit(raw_train_labels)
train_labels = encoder.transform(raw_train_labels)
test_labels = encoder.transform(raw_test_labels)
Bringing Your Own Data (BYOD)?
You can easily replace the above with your own text dataset, and continue with the rest of the tutorial.
Your classes (and entries of train_labels / test_labels) should be represented as integer indices 0, 1, …, num_classes - 1. For example, if your dataset has 7 examples from 3 classes, train_labels might be: np.array([2,0,0,1,2,0,1])
Next we convert the text strings into vectors better suited as inputs for our ML model.
We will use numeric representations from a pretrained Transformer model as embeddings of our text. The Sentence Transformers library offers simple methods to compute these embeddings for text data. Here, we load the pretrained electra-small-discriminator model, and then run our data through network to extract a vector embedding of each example.
[9]:
transformer = SentenceTransformer('google/electra-small-discriminator')
train_texts = transformer.encode(raw_train_texts)
test_texts = transformer.encode(raw_test_texts)
No sentence-transformers model found with name /home/runner/.cache/torch/sentence_transformers/google_electra-small-discriminator. Creating a new one with MEAN pooling.
Our subsequent ML model will directly operate on elements of train_texts and test_texts in order to classify the customer service requests.
3. Define a classification model and use cleanlab to find potential label errors#
A typical way to leverage pretrained networks for a particular classification task is to add a linear output layer and fine-tune the network parameters on the new data. However this can be computationally intensive. Alternatively, we can freeze the pretrained weights of the network and only train the output layer without having to rely on GPU(s). Here we do this conveniently by fitting a scikit-learn linear model on top of the extracted embeddings.
[10]:
model = LogisticRegression(max_iter=400)
We can define the CleanLearning object with our Logistic Regression model and use find_label_issues to identify potential label errors.
CleanLearning provides a wrapper class that can easily be applied to any scikit-learn compatible model, which can be used to find potential label issues and train a more robust model if the original data contains noisy labels.
[11]:
cv_n_folds = 5 # for efficiency; values like 5 or 10 will generally work better
cl = CleanLearning(model, cv_n_folds=cv_n_folds)
[12]:
label_issues = cl.find_label_issues(X=train_texts, labels=train_labels)
The find_label_issues method above will perform cross validation to compute out-of-sample predicted probabilites for each example, which is used to identify label issues.
This method returns a dataframe containing a label quality score for each example. These numeric scores lie between 0 and 1, where lower scores indicate examples more likely to be mislabeled. The dataframe also contains a boolean column specifying whether or not each example is identified to have a label issue (indicating it is likely mislabeled). Note that the given and predicted labels here are encoded as intergers as that was the format expected by cleanlab, we will inverse transform them
later in this tutorial.
[13]:
label_issues.head()
[13]:
| is_label_issue | label_quality | given_label | predicted_label | |
|---|---|---|---|---|
| 0 | False | 0.858371 | 6 | 6 |
| 1 | False | 0.547274 | 3 | 3 |
| 2 | False | 0.826228 | 7 | 7 |
| 3 | False | 0.966008 | 8 | 8 |
| 4 | False | 0.792449 | 4 | 4 |
We can get the subset of examples flagged with label issues, and also sort by label quality score to find the indices of the 10 most likely mislabeled examples in our dataset.
[14]:
identified_issues = label_issues[label_issues["is_label_issue"] == True]
lowest_quality_labels = label_issues["label_quality"].argsort()[:10].to_numpy()
[15]:
print(
f"cleanlab found {len(identified_issues)} potential label errors in the dataset.\n"
f"Here are indices of the top 10 most likely errors: \n {lowest_quality_labels}"
)
cleanlab found 44 potential label errors in the dataset.
Here are indices of the top 10 most likely errors:
[646 390 628 121 702 863 456 135 337 735]
Let’s review some of the most likely label errors. To help us inspect these datapoints, we define a method to print any example from the dataset, together with its given (original) label and the suggested alternative label from cleanlab.
We then display some of the top-ranked label issues identified by cleanlab:
[16]:
def print_as_df(index):
return pd.DataFrame(
{
"text": raw_train_texts,
"given_label": raw_train_labels,
"predicted_label": encoder.inverse_transform(label_issues["predicted_label"]),
},
).iloc[index]
[17]:
print_as_df(lowest_quality_labels[:5])
[17]:
| text | given_label | predicted_label | |
|---|---|---|---|
| 646 | i was charged for getting cash. | card_about_to_expire | card_payment_fee_charged |
| 390 | can i change my pin on holiday? | beneficiary_not_allowed | change_pin |
| 628 | will i be sent a new card before mine expires? | apple_pay_or_google_pay | card_about_to_expire |
| 121 | Would you rather fight one horse-sized duck or 100 duck-sized horses? | lost_or_stolen_phone | getting_spare_card |
| 702 | please tell me how to change my pin. | beneficiary_not_allowed | change_pin |
These are very clear label errors that cleanlab has identified in this data! Note that the given_label does not correctly reflect the intent of these requests, whoever produced this dataset made many mistakes that are important to address before modeling the data.
cleanlab has shortlisted the most likely label errors to speed up your data cleaning process. With this list, you can decide whether to fix these label issues or remove ambiguous examples from the dataset.
4. Train a more robust model from noisy labels#
Fixing the label issues manually may be time-consuming, but cleanlab can filter these noisy examples and train a model on the remaining clean data for you automatically.
To establish a baseline, let’s first train and evaluate our original Logistic Regression model.
[18]:
baseline_model = LogisticRegression(max_iter=400) # note we first re-instantiate the model
baseline_model.fit(X=train_texts, y=train_labels)
preds = baseline_model.predict(test_texts)
acc_og = accuracy_score(test_labels, preds)
print(f"\n Test accuracy of original model: {acc_og}")
Test accuracy of original model: 0.87
Now that we have a baseline, let’s check if using CleanLearning improves our test accuracy.
CleanLearning provides a wrapper that can be applied to any scikit-learn compatible model. The resulting model object can be used in the same manner, but it will now train more robustly if the data has noisy labels.
We can use the same CleanLearning object defined above, and pass the label issues we already computed into .fit() via the label_issues argument. This accelerates things; if we did not provide the label issues, then they would be recomputed via cross-validation. After that CleanLearning simply deletes the examples with label issues and retrains your model on the remaining data.
[19]:
cl.fit(X=train_texts, labels=train_labels, label_issues=cl.get_label_issues())
pred_labels = cl.predict(test_texts)
acc_cl = accuracy_score(test_labels, pred_labels)
print(f"Test accuracy of cleanlab's model: {acc_cl}")
Test accuracy of cleanlab's model: 0.89
We can see that the test set accuracy slightly improved as a result of the data cleaning. Note that this will not always be the case, especially when we are evaluating on test data that are themselves noisy. The best practice is to run cleanlab to identify potential label issues and then manually review them, before blindly trusting any accuracy metrics. In particular, the most effort should be made to ensure high-quality test data, which is supposed to reflect the expected performance of our model during deployment.
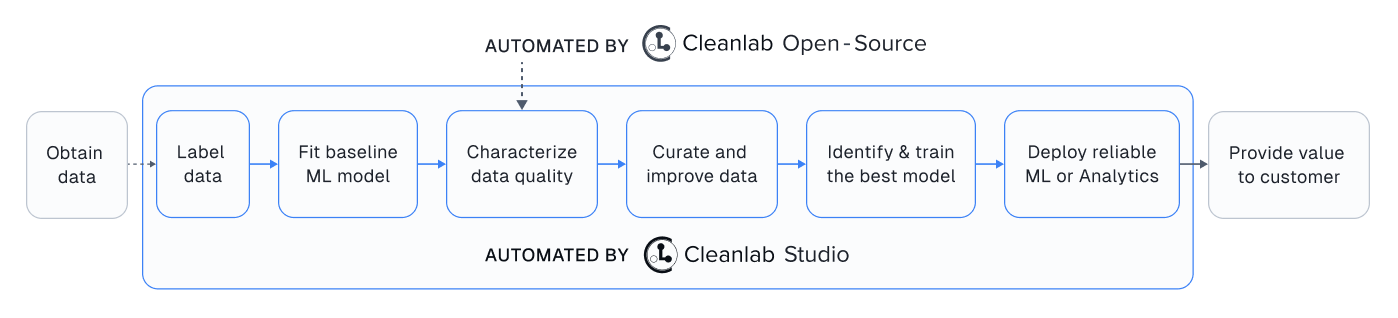
Spending too much time on data quality?#
Using this open-source package effectively can require significant ML expertise and experimentation, plus handling detected data issues can be cumbersome.
That’s why we built Cleanlab Studio – an automated platform to find and fix issues in your dataset, 100x faster and more accurately. Cleanlab Studio automatically runs optimized data quality algorithms from this package on top of cutting-edge AutoML & Foundation models fit to your data, and helps you fix detected issues via a smart data correction interface. Try it for free!