Find Label Errors in Multi-Label Classification Datasets#
This 5-minute quickstart tutorial demonstrates how to find potential label errors in multi-label classification datasets. In such datasets, each example is labeled as belonging to one or more classes (unlike in multi-class classification where each example can only belong to one class). For a particular example in such multi-label classification data, we say each class either applies or not. We may even have some examples where no classes apply. Common applications of this include image
tagging (or document tagging), where multiple tags can be appropriate for a single image (or document). For example, a image tagging application could involve the following classes: [copyrighted, advertisement, face, violence, nsfw]
Quickstart
cleanlab finds data/label issues based on two inputs: labels formatted as a list of lists of integer class indices that apply to each example in your dataset, and pred_probs from a trained multi-label classification model (which do not need to sum to 1 since the classes are not mutually exclusive). Once you have these, run the code below to find issues in your multi-label dataset:
from cleanlab import Datalab
# Assuming your dataset has a label column named 'label'
lab = Datalab(dataset, label_name='label', task='multilabel')
# To detect more issue types, optionally supply `features` (numeric dataset values or model embeddings of the data)
lab.find_issues(pred_probs=pred_probs, features=features)
lab.report()
1. Install required dependencies and get dataset#
You can use pip to install all packages required for this tutorial as follows:
!pip install matplotlib
!pip install "cleanlab[datalab]"
# Make sure to install the version corresponding to this tutorial
# E.g. if viewing master branch documentation:
# !pip install git+https://github.com/cleanlab/cleanlab.git
[2]:
import random
import numpy as np
import sklearn
from sklearn.multiclass import OneVsRestClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold
import matplotlib.pyplot as plt
from cleanlab import Datalab
from cleanlab.internal.multilabel_utils import int2onehot, onehot2int
Here we generate a small multi-label classification dataset for a quick demo. To see cleanlab applied to a real image tagging dataset, check out our example notebook “Find Label Errors in Multi-Label Classification Data (CelebA Image Tagging)”.
Code to generate dataset (can skip these details) (click to expand)
# Note: This pulldown content is for docs.cleanlab.ai, if running on local Jupyter or Colab, please ignore it.
from cleanlab.benchmarking.noise_generation import (
generate_noise_matrix_from_trace,
generate_noisy_labels,
)
def make_multilabel_data(
means=[[-5, 3.5], [0, 2], [-3, 6]],
covs=[[[3, -1.5], [-1.5, 1]], [[5, -1.5], [-1.5, 1]], [[3, -1.5], [-1.5, 1]]],
boxes_coordinates=[[-3.5, 0, -1.5, 1.7], [-1, 3, 2, 4], [-5, 2, -3, 4], [-3, 2, -1, 4]],
box_multilabels=[[0, 1], [1, 2], [0, 2], [0, 1, 2]],
sizes=[100, 80, 100],
avg_trace=0.9,
seed=1,
):
np.random.seed(seed=seed)
num_classes = len(means)
m = num_classes + len(
box_multilabels
) # number of classes by treating each multilabel as 1 unique label
n = sum(sizes)
local_data = []
labels = []
test_data = []
test_labels = []
for i in range(0, len(means)):
local_data.append(np.random.multivariate_normal(mean=means[i], cov=covs[i], size=sizes[i]))
test_data.append(np.random.multivariate_normal(mean=means[i], cov=covs[i], size=sizes[i]))
test_labels += [[i]] * sizes[i]
labels += [[i]] * sizes[i]
def make_multi(X, Y, bx1, by1, bx2, by2, label_list):
ll = np.array([bx1, by1]) # lower-left
ur = np.array([bx2, by2]) # upper-right
inidx = np.all(np.logical_and(X.tolist() >= ll, X.tolist() <= ur), axis=1)
for i in range(0, len(Y)):
if inidx[i]:
Y[i] = label_list
return Y
X_train = np.vstack(local_data)
X_test = np.vstack(test_data)
for i in range(0, len(box_multilabels)):
bx1, by1, bx2, by2 = boxes_coordinates[i]
multi_label = box_multilabels[i]
labels = make_multi(X_train, labels, bx1, by1, bx2, by2, multi_label)
test_labels = make_multi(X_test, test_labels, bx1, by1, bx2, by2, multi_label)
d = {}
for i in labels:
if str(i) not in d:
d[str(i)] = len(d)
inv_d = {v: k for k, v in d.items()}
labels_idx = [d[str(i)] for i in labels]
py = np.bincount(labels_idx) / float(len(labels_idx))
noise_matrix = generate_noise_matrix_from_trace(
m,
trace=avg_trace * m,
py=py,
valid_noise_matrix=True,
seed=seed,
)
noisy_labels_idx = generate_noisy_labels(labels_idx, noise_matrix)
noisy_labels = [eval(inv_d[i]) for i in noisy_labels_idx]
return {
"X_train": X_train,
"true_labels_train": labels,
"X_test": X_test,
"true_labels_test": test_labels,
"labels": noisy_labels,
"dict_unique_label": d,
'labels_idx': noisy_labels_idx,
}
def get_color_array(labels):
"""
This function returns a dictionary mapping multi-labels to unique colors
"""
dcolors ={'[0]': 'aa4400',
'[0, 2]': '55227f',
'[0, 1]': '55a100',
'[1]': '00ff00',
'[1, 2]': '007f7f',
'[0, 1, 2]': '386b55',
'[2]': '0000ff'}
return ["#"+dcolors[str(i)] for i in labels]
def plot_data(data, circles, title, alpha=1.0,colors = []):
plt.figure(figsize=(14, 5))
done = set()
for i in range(0,len(data)):
lab = str(labels[i])
if lab in done:
label = ""
else:
label = lab
done.add(lab)
plt.scatter(data[i, 0], data[i, 1], c=colors[i], s=30,alpha=0.6, label = label)
for i in circles:
plt.plot(
data[i][0],
data[i][1],
"o",
markerfacecolor="none",
markeredgecolor="red",
markersize=14,
markeredgewidth=2.5,
alpha=alpha
)
_ = plt.title(title, fontsize=25)
plt.legend()
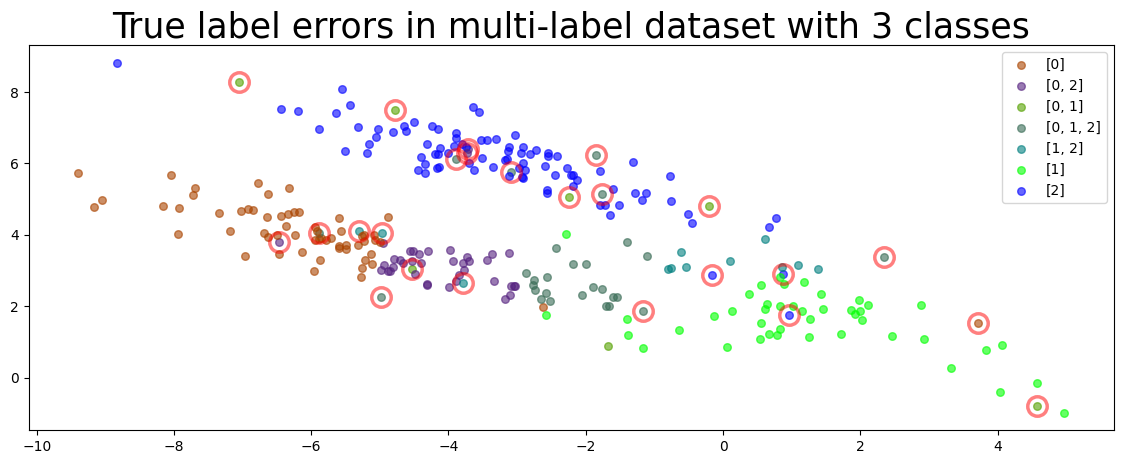
Some of the labels in our generated dataset purposely contain errors. The examples with label errors are circled in the plot below, which depicts the dataset. This dataset contains 3 classes, and any subset of these may be the given label for a particular example. We say this example has a label error if it is better described by an alternative subset of the classes than the given label.
[4]:
num_class = 3
dataset = make_multilabel_data()
labels = dataset['labels']
true_errors = np.where(np.sum(int2onehot(dataset['true_labels_train'],3)!=int2onehot(dataset['labels'],3),axis=1)>=1)[0]
plot_data(dataset['X_train'], circles=true_errors, title=f"True label errors in multi-label dataset with {num_class} classes", colors = get_color_array(labels),alpha=0.5)
2. Format data, labels, and model predictions#
In multi-label classification, each example in the dataset is labeled as belonging to one or more of K possible classes (or none of the classes at all). To find label issues, cleanlab requires predicted class probabilities from a trained classifier. Here we produce out-of-sample pred_probs by employing cross-validation to fit a multi-label RandomForestClassifier model via sklearn’s
OneVsRestClassifier framework. Make sure that the columns of your pred_probs are properly ordered with respect to the ordering of classes, which for Datalab is: lexicographically sorted by class name. OneVsRestClassifier offers an easy way to apply any multi-class classifier model from sklearn to multi-label classification tasks. It is done for simplicity here, but we advise against this
approach as it does not properly model dependencies between classes.
To instead train a state-of-the-art Pytorch neural network for multi-label classification and produce pred_probs on a real image dataset (that properly account for dependencies between classes), see our example notebook “Train a neural network for multi-label classification on the CelebA dataset”.
[5]:
SEED = 0
random.seed(SEED)
y_onehot = int2onehot(labels, K=num_class) # labels in a binary format for sklearn OneVsRestClassifier
single_class_labels = [random.choice(i) for i in labels] # used only for stratifying the cross-validation split
clf = OneVsRestClassifier(RandomForestClassifier(random_state=SEED))
pred_probs = np.zeros(shape=(len(labels), num_class))
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=SEED)
for train_index, test_index in kf.split(X=dataset['X_train'], y=single_class_labels):
clf_cv = sklearn.base.clone(clf)
X_train_cv, X_test_cv = dataset['X_train'][train_index], dataset['X_train'][test_index]
y_train_cv, y_test_cv = y_onehot[train_index], y_onehot[test_index]
clf_cv.fit(X_train_cv, y_train_cv)
y_pred_cv = clf_cv.predict_proba(X_test_cv)
pred_probs[test_index] = y_pred_cv
pred_probs should be 2D array whose rows are length-K vectors for each example in the dataset, representing the model-estimated probability that this example belongs to each class. Since one example can belong to multiple classes in multi-label classification, these probabilities need not sum to 1. For the best label error detection performance, these pred_probs should be out-of-sample (from a copy of the model that never saw this example during training, e.g. produced via
cross-validation).
labels should be a list of lists, whose i-th entry is a list of (integer) class indices that apply to the i-th example in the dataset. If your classes are represented as string names, you should map these to integer indices. The label for an example that belongs to none of the classes should just be an empty list [].
Once you have pred_probs and labels appropriately formatted, you can find/analyze label issues in any multi-label dataset via Datalab!
Here’s what these look like for the first few examples in our synthetic multi-label dataset:
[6]:
num_to_display = 3 # increase this to see more examples
print(f"labels for first {num_to_display} examples in format expected by cleanlab:")
print(labels[:num_to_display])
print(f"pred_probs for first {num_to_display} examples in format expected by cleanlab:")
print(pred_probs[:num_to_display])
labels for first 3 examples in format expected by cleanlab:
[[0], [0, 2], [0]]
pred_probs for first 3 examples in format expected by cleanlab:
[[1. 0. 0. ]
[0.96 0.09 0.88]
[1. 0.01 0.22]]
3. Use cleanlab to find label issues#
Based on the given labels and pred_probs from a trained model, cleanlab can quickly help us find label errors in our dataset.
[7]:
lab = Datalab(
data={"labels": labels},
label_name="labels",
task="multilabel",
)
lab.find_issues(
pred_probs=pred_probs,
issue_types={"label": {}}
)
Finding label issues ...
Audit complete. 30 issues found in the dataset.
Here we request that the indices of the examples identified with label issues be sorted by cleanlab’s self-confidence score, which is used to measure the quality of individual labels. The returned issues are a list of indices corresponding to the examples in your dataset that cleanlab finds most likely to be mislabeled. These indices are sorted by the self-confidence label quality score, with the lowest quality labels at the start.
[8]:
label_issues = lab.get_issues("label")
issues = label_issues.query("is_label_issue").sort_values("label_score").index.values
print(f"Indices of examples with label issues:\n{issues}")
Indices of examples with label issues:
[275 267 225 72 171 234 165 44 6 29 227 188 102 262 263 35 266 139
143 172 53 216 265 176 164 73 75 10 159 107]
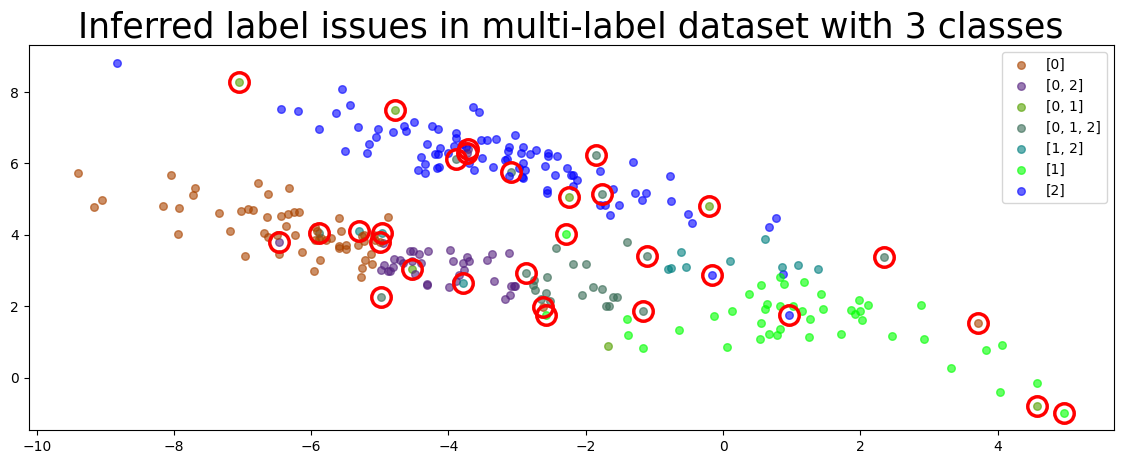
Let’s look at the samples that cleanlab thinks are most likely to be mislabeled. You can see that cleanlab was able to identify most of true_errors in our small dataset (despite not having access to this variable, which you won’t have in your own applications).
[9]:
plot_data(dataset['X_train'], circles=issues, title=f"Inferred label issues in multi-label dataset with {num_class} classes", colors = get_color_array(labels), alpha = 1)
Label quality scores#
The above code identifies which examples have label issues and sorts them by their label quality score. We can also take a look at this label quality score for each example in the dataset, which estimates our confidence that this example has been correctly labeled. These scores range between 0 and 1 with smaller values indicating examples whose label seems more suspect.
[10]:
scores = label_issues["label_score"].values
print(f"Label quality scores of the first 10 examples in dataset:\n{scores[:10]}")
Label quality scores of the first 10 examples in dataset:
[1. 0.888 0.8224 0.9632 0.968 0.6512 0.0444 1. 0.76 0.774 ]
Data issues beyond mislabeling (outliers, duplicates, drift, …)#
While this tutorial focused on label issues, cleanlab’s Datalab object can automatically detect many other types of issues in your dataset (outliers, near duplicates, drift, etc). Simply remove the issue_types argument from the above call to Datalab.find_issues() above and Datalab will more comprehensively audit your dataset. Refer to our Datalab quickstart tutorial to learn how to interpret the results (the interpretation remains mostly
the same across different types of ML tasks).
How to format labels given as a one-hot (multi-hot) binary matrix?#
For multi-label classification, cleanlab expects labels to be formatted as a list of lists, where each entry is an integer corresponding to a particular class. Here are some functions you can use to easily convert labels between this format and a binary matrix format commonly used to train multi-label classification models.
[11]:
labels_binary_format = int2onehot(labels, K=num_class)
labels_list_format = onehot2int(labels_binary_format)
Estimate label issues without Datalab#
If you prefer to directly run the same lower-level mathematical functions Datalab uses to detect label issues, you can do so outside of Datalab via the methods in the cleanlab.multilabel_classification module such as: multilabel_classification.filter.find_label_issues,
multilabel_classification.rank.get_label_quality_scores
Application to Real Data#
To see cleanlab applied to a real image tagging dataset, check out our example notebook “Find Label Errors in Multi-Label Classification Data (CelebA Image Tagging)”. That example also demonstrates how to use a state-of-the-art Pytorch neural network for multi-label classification with image data.