Datalab Issue Types#
Types of issues Datalab can detect#
This page describes the various types of issues that Datalab can detect in a dataset. For each type of issue, we explain: what it says about your data if detected, why this matters, and what parameters you can optionally specify to control the detection of this issue.
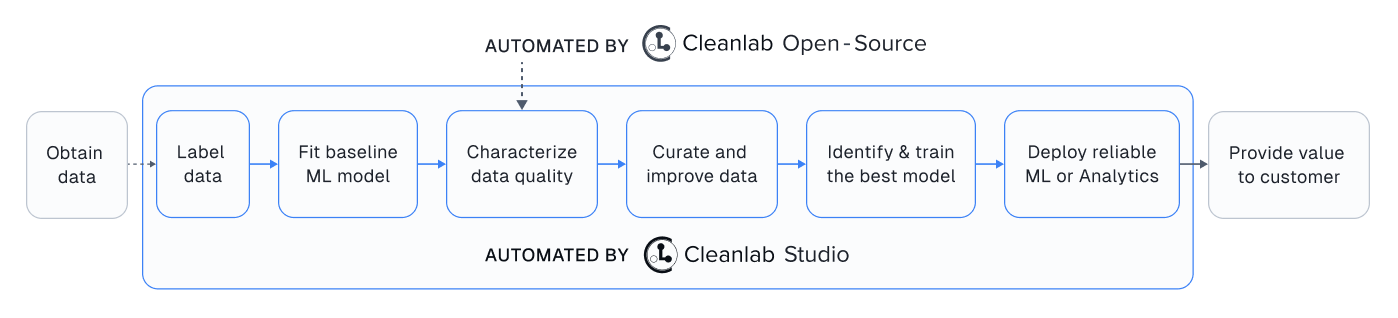
In case you didn’t know: you can alternatively use Cleanlab Studio to detect the same data issues as this package, plus many more types of issues, all without having to do any Machine Learning (or even write any code).
Estimates for Each Issue Type#
Datalab produces three estimates for each type of issue (called say <ISSUE_NAME> here):
A numeric quality score
<ISSUE_NAME>_score(between 0 and 1) estimating how severe this issue is exhibited in each example from a dataset. Examples with higher scores are less likely to suffer from this issue. Access these via: theDatalab.issuesattribute or the methodDatalab.get_issues(<ISSUE_NAME>).A Boolean
is_<ISSUE_NAME>_issueflag for each example from a dataset. Examples where this has valueTrueare those estimated to exhibit this issue. Access these via: theDatalab.issuesattribute or the methodDatalab.get_issues(<ISSUE_NAME>).An overall dataset quality score (between 0 and 1), quantifying how severe this issue is overall across the entire dataset. Datasets with higher scores do not exhibit this issue as badly overall. Access these via: the
Datalab.issue_summaryattribute.
Example (for the outlier issue type)
issue_name = "outlier" # how to reference the outlier issue type in code
issue_score = "outlier_score" # name of column with quality scores for the outlier issue type, atypical datapoints receive lower scores
is_issue = "is_outlier_issue" # name of Boolean column flagging which datapoints are considered outliers in the dataset
Datalab estimates various issues based on the four inputs below. Each input is optional, if you do not provide it, Datalab will skip checks for those types of issues that require this input.
label_name- a field in the dataset that the stores the annotated class for each example in a multi-class classification dataset.pred_probs- predicted class probabilities output by your trained model for each example in the dataset (these should be out-of-sample, eg. produced via cross-validation).features- numeric vector representations of the features for each example in the dataset. These may be embeddings from a (pre)trained model, or just a numerically-transformed version of the original data features.knn_graph- K nearest neighbor graph represented as a sparse matrix of dissimilarity values between examples in the dataset. If bothknn_graphandfeaturesare provided, theknn_graphtakes precedence, and if onlyfeaturesis provided, then aknn_graphis internally constructed based on the (either euclidean or cosine) distance between different examples’ features.
Label Issue#
Examples whose given label is estimated to be potentially incorrect (e.g. due to annotation error) are flagged as having label issues. Datalab estimates which examples appear mislabeled as well as a numeric label quality score for each, which quantifies the likelihood that an example is correctly labeled.
For now, Datalab can only detect label issues in multi-class classification datasets, regression datasets, and multi-label classification datasets. The cleanlab library has alternative methods you can us to detect label issues in other types of datasets (multi-annotator, token classification, etc.).
Label issues are calculated based on provided pred_probs from a trained model. If you do not provide this argument, but you do provide features, then a K Nearest Neighbor model will be fit to produce pred_probs based on your features. Otherwise if neither pred_probs nor features is provided, then this type of issue will not be considered.
For the most accurate results, provide out-of-sample pred_probs which can be obtained for a dataset via cross-validation.
Having mislabeled examples in your dataset may hamper the performance of supervised learning models you train on this data. For evaluating models or performing other types of data analytics, mislabeled examples may lead you to draw incorrect conclusions. To handle mislabeled examples, you can either filter out the data with label issues or try to correct their labels.
Learn more about the method used to detect label issues in our paper: Confident Learning: Estimating Uncertainty in Dataset Labels
Tip
This type of issue has the issue name "label".
Run a check for this particular kind of issue by calling Datalab.find_issues() like so:
# `lab` is a Datalab instance
lab.find_issues(..., issue_types = {"label": {}})
Outlier Issue#
Examples that are very different from the rest of the dataset (i.e. potentially out-of-distribution or rare/anomalous instances).
Outlier issues are calculated based on provided features , knn_graph , or pred_probs.
If you do not provide one of these arguments, this type of issue will not be considered.
This article describes how outlier issues are detected in a dataset: https://cleanlab.ai/blog/outlier-detection/.
When based on features or knn_graph, the outlier quality of each example is scored inversely proportional to its distance to its K nearest neighbors in the dataset.
When based on pred_probs, the outlier quality of each example is scored inversely proportional to the uncertainty in its prediction.
Modeling data with outliers may have unexpected consequences. Closely inspect them and consider removing some outliers that may be negatively affecting your models.
Learn more about the methods used to detect outliers in our article: Out-of-Distribution Detection via Embeddings or Predictions
Tip
This type of issue has the issue name "outlier".
Run a check for this particular kind of issue by calling Datalab.find_issues() like so:
# `lab` is a Datalab instance
lab.find_issues(..., issue_types = {"outlier": {}})
(Near) Duplicate Issue#
A (near) duplicate issue refers to two or more examples in a dataset that are extremely similar to each other, relative to the rest of the dataset. The examples flagged with this issue may be exactly duplicated, or lie atypically close together when represented as vectors (i.e. feature embeddings). Near duplicated examples may record the same information with different:
Abbreviations, misspellings, typos, formatting, etc. in text data.
Compression formats, resolutions, or sampling rates in image, video, and audio data.
Minor variations which naturally occur in many types of data (e.g. translated versions of an image).
Near Duplicate issues are calculated based on provided features or knn_graph.
If you do not provide one of these arguments, this type of issue will not be considered.
Datalab defines near duplicates as those examples whose distance to their nearest neighbor (in the space of provided features) in the dataset is less than c * D, where 0 < c < 1 is a small constant, and D is the median (over the full dataset) of such distances between each example and its nearest neighbor.
Scoring the numeric quality of an example in terms of the near duplicate issue type is done proportionally to its distance to its nearest neighbor.
Including near-duplicate examples in a dataset may negatively impact a ML model’s generalization performance and lead to overfitting. In particular, it is questionable to include examples in a test dataset which are (nearly) duplicated in the corresponding training dataset. More generally, examples which happen to be duplicated can affect the final modeling results much more than other examples — so you should at least be aware of their presence.
Tip
This type of issue has the issue name "near_duplicate".
Run a check for this particular kind of issue by calling Datalab.find_issues() like so:
# `lab` is a Datalab instance
lab.find_issues(..., issue_types = {"near_duplicate": {}})
Non-IID Issue#
Whether the dataset exhibits statistically significant violations of the IID assumption like: changepoints or shift, drift, autocorrelation, etc. The specific form of violation considered is whether the examples are ordered such that almost adjacent examples tend to have more similar feature values. If you care about this check, do not first shuffle your dataset – this check is entirely based on the sequential order of your data.
The Non-IID issue is detected based on provided features or knn_graph. If you do not provide one of these arguments, this type of issue will not be considered.
Mathematically, the overall Non-IID score for the dataset is defined as the p-value of a statistical test for whether the distribution of index-gap values differs between group A vs. group B defined as follows. For a pair of examples in the dataset x1, x2, we define their index-gap as the distance between the indices of these examples in the ordering of the data (e.g. if x1 is the 10th example and x2 is the 100th example in the dataset, their index-gap is 90). We construct group A from pairs of examples which are amongst the K nearest neighbors of each other, where neighbors are defined based on the provided knn_graph or via distances in the space of the provided vector features . Group B is constructed from random pairs of examples in the dataset.
The Non-IID quality score for each example x is defined via a similarly computed p-value but with Group A constructed from the K nearest neighbors of x and Group B constructed from random examples from the dataset paired with x. Learn more about the math behind this method in our paper: Detecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors
The assumption that examples in a dataset are Independent and Identically Distributed (IID) is fundamental to most proper modeling. Detecting all possible violations of the IID assumption is statistically impossible. This issue type only considers specific forms of violation where examples that tend to be closer together in the dataset ordering also tend to have more similar feature values. This includes scenarios where:
The underlying distribution from which examples stem is evolving over time (not identically distributed).
An example can influence the values of future examples in the dataset (not independent).
For datasets with low non-IID score, you should consider why your data are not IID and act accordingly. For example, if the data distribution is drifting over time, consider employing a time-based train/test split instead of a random partition. Note that shuffling the data ahead of time will ensure a good non-IID score, but this is not always a fix to the underlying problem (e.g. future deployment data may stem from a different distribution, or you may overlook the fact that examples influence each other). We thus recommend not shuffling your data to be able to diagnose this issue if it exists.
Tip
This type of issue has the issue name "non_iid".
Run a check for this particular kind of issue by calling Datalab.find_issues() like so:
# `lab` is a Datalab instance
lab.find_issues(..., issue_types = {"non_iid": {}})
Class Imbalance Issue#
Class imbalance is diagnosed just using the labels provided as part of the dataset. The overall class imbalance quality score of a dataset is the proportion of examples belonging to the rarest class q. If this proportion q falls below a threshold, then we say this dataset suffers from the class imbalance issue.
In a dataset identified as having class imbalance, the class imbalance quality score for each example is set equal to q if it is labeled as the rarest class, and is equal to 1 for all other examples.
Class imbalance in a dataset can lead to subpar model performance for the under-represented class. Consider collecting more data from the under-represented class, or at least take special care while modeling via techniques like over/under-sampling, SMOTE, asymmetric class weighting, etc.
Tip
This type of issue has the issue name "class_imbalance".
Run a check for this particular kind of issue by calling Datalab.find_issues() like so:
# `lab` is a Datalab instance
lab.find_issues(..., issue_types = {"class_imbalance": {}})
Image-specific Issues#
For image datasets which are properly specified as such, Datalab can detect additional types of image-specific issues (if the necessary optional dependencies are installed). Specifically, low-quality images which are too: dark/bright, blurry, low information, abnormally sized, etc. Descriptions of these image-specific issues are provided in the CleanVision package and its documentation.
Underperforming Group Issue#
An underperforming group refers to a cluster of similar examples (i.e. a slice) in the dataset for which the ML model predictions are poor. The examples in this underperforming group may have noisy labels or feature values, or the trained ML model may not have learned how to properly handle them (consider collecting more data from this subpopulation or up-weighting the existing data from this group).
Underperforming Group issues are detected based on one of:
provided
pred_probsandfeatures,provided
pred_probsandknn_graph, orprovided
pred_probsandcluster_ids. (This option is for advanced users, see the FAQ for more details.)
If you do not provide both these arguments, this type of issue will not be considered.
To find the underperforming group, Cleanlab clusters the data using the provided features and determines the cluster c with the lowest average model predictive performance. Model predictive performance is evaluated via the model’s self-confidence of the given labels, calculated using rank.get_self_confidence_for_each_label. Suppose the average predictive power across the full dataset is r and is q within a cluster of examples. This cluster is considered to be an underperforming group if q/r falls below a threshold. A dataset suffers from the Underperforming Group issue if there exists such a cluster within it.
The underperforming group quality score is equal to q/r for examples belonging to the underperforming group, and is equal to 1 for all other examples.
Advanced users: If you have pre-computed cluster assignments for each example in the dataset, you can pass them explicitly to Datalab.find_issues using the cluster_ids key in the issue_types dict argument. This is useful for tabular datasets where you want to group/slice the data based on a categorical column. An integer encoding of the categorical column can be passed as cluster assignments for finding the underperforming group, based on the data slices you define.
Tip
This type of issue has the issue name "underperforming_group".
Run a check for this particular kind of issue by calling Datalab.find_issues() like so:
# `lab` is a Datalab instance
lab.find_issues(..., issue_types = {"underperforming_group": {}})
Null Issue#
Examples identified with the null issue correspond to rows that have null/missing values across all feature columns (i.e. the entire row is missing values).
Null issues are detected based on provided features. If you do not provide features, this type of issue will not be considered.
Each example’s null issue quality score equals the proportion of features values in this row that are not null/missing. The overall dataset null issue quality score equals the average of the individual examples’ quality scores.
Presence of null examples in the dataset can lead to errors when training ML models. It can also result in the model learning incorrect patterns due to the null values.
Tip
This type of issue has the issue name "null".
Run a check for this particular kind of issue by calling Datalab.find_issues() like so:
# `lab` is a Datalab instance
lab.find_issues(..., issue_types = {"null": {}})
Data Valuation Issue#
The examples in the dataset with lowest data valuation scores contribute least to a trained ML model’s performance (those whose value falls below a threshold are flagged with this type of issue).
Data valuation issues can only be detected based on a provided knn_graph (or one pre-computed during the computation of other issue types). If you do not provide this argument and there isn’t a knn_graph already stored in the Datalab object, this type of issue will not be considered.
The data valuation score is an approximate Data Shapley value, calculated based on the labels of the top k nearest neighbors of an example. The details of this KNN-Shapley value could be found in the papers: Efficient Task-Specific Data Valuation for Nearest Neighbor Algorithms and Scalability vs. Utility: Do We Have to Sacrifice One for the Other in Data Importance Quantification?.
Tip
This type of issue has the issue name "data_valuation".
Run a check for this particular kind of issue by calling Datalab.find_issues() like so:
# `lab` is a Datalab instance
lab.find_issues(..., issue_types = {"data_valuation": {}})
Optional Issue Parameters#
Here is the dict of possible (optional) parameter values that can be specified via the argument issue_types to Datalab.find_issues.
Optionally specify these to exert greater control over how issues are detected in your dataset.
Appropriate defaults are used for any parameters you do not specify, so no need to specify all of these!
possible_issue_types = {
"label": label_kwargs, "outlier": outlier_kwargs,
"near_duplicate": near_duplicate_kwargs, "non_iid": non_iid_kwargs,
"class_imbalance": class_imbalance_kwargs, "underperforming_group": underperforming_group_kwargs,
"null": null_kwargs, "data_valuation": data_valuation_kwargs,
}
where the possible kwargs dicts for each key are described in the sections below.
Label Issue Parameters#
label_kwargs = {
"k": # number of nearest neighbors to consider when computing pred_probs from features,
"health_summary_parameters": # dict of potential keyword arguments to method `dataset.health_summary()`,
"clean_learning_kwargs": # dict of keyword arguments to constructor `CleanLearning()` including keys like: "find_label_issues_kwargs" or "label_quality_scores_kwargs",
"thresholds": # `thresholds` argument to `CleanLearning.find_label_issues()`,
"noise_matrix": # `noise_matrix` argument to `CleanLearning.find_label_issues()`,
"inverse_noise_matrix": # `inverse_noise_matrix` argument to `CleanLearning.find_label_issues()`,
"save_space": # `save_space` argument to `CleanLearning.find_label_issues()`,
"clf_kwargs": # `clf_kwargs` argument to `CleanLearning.find_label_issues()`. Currently has no effect.,
"validation_func": # `validation_func` argument to `CleanLearning.fit()`. Currently has no effect.,
}
Attention
health_summary_parameters and health_summary_kwargs can work in tandem to determine the arguments to be used in the call to dataset.health_summary.
Note
For more information, view the source code of: datalab.internal.issue_manager.label.LabelIssueManager.
Outlier Issue Parameters#
outlier_kwargs = {
"threshold": # floating value between 0 and 1 that sets the sensitivity of the outlier detection algorithms, based on either features or pred_probs..
"ood_kwargs": # dict of keyword arguments to constructor `OutOfDistribution()`{
"params": {
# NOTE: Each of the following keyword arguments can also be provided outside "ood_kwargs"
"knn": # `knn` argument to constructor `OutOfDistribution()`. Used with features,
"k": # `k` argument to constructor `OutOfDistribution()`. Used with features,
"t": # `t` argument to constructor `OutOfDistribution()`. Used with features,
"adjust_pred_probs": # `adjust_pred_probs` argument to constructor `OutOfDistribution()`. Used with pred_probs,
"method": # `method` argument to constructor `OutOfDistribution()`. Used with pred_probs,
"confident_thresholds": # `confident_thresholds` argument to constructor `OutOfDistribution()`. Used with pred_probs,
},
},
}
Note
For more information, view the source code of: datalab.internal.issue_manager.outlier.OutlierIssueManager.
Duplicate Issue Parameters#
near_duplicate_kwargs = {
"metric": # string representing the distance metric used in nearest neighbors search (passed as argument to `NearestNeighbors`), if necessary,
"k": # integer representing the number of nearest neighbors for nearest neighbors search (passed as argument to `NearestNeighbors`), if necessary,
"threshold": # `threshold` argument to constructor of `NearDuplicateIssueManager()`. Non-negative floating value that determines the maximum distance between two examples to be considered outliers, relative to the median distance to the nearest neighbors,
}
Attention
k does not affect the results of the (near) duplicate search algorithm. It only affects the construction of the knn graph, if necessary.
Note
For more information, view the source code of: datalab.internal.issue_manager.duplicate.NearDuplicateIssueManager.
Non-IID Issue Parameters#
non_iid_kwargs = {
"metric": # `metric` argument to constructor of `NonIIDIssueManager`. String for the distance metric used for nearest neighbors search if necessary. `metric` argument to constructor of `sklearn.neighbors.NearestNeighbors`,
"k": # `k` argument to constructor of `NonIIDIssueManager`. Integer representing the number of nearest neighbors for nearest neighbors search if necessary. `n_neighbors` argument to constructor of `sklearn.neighbors.NearestNeighbors`,
"num_permutations": # `num_permutations` argument to constructor of `NonIIDIssueManager`,
"seed": # seed for numpy's random number generator (used for permutation tests),
"significance_threshold": # `significance_threshold` argument to constructor of `NonIIDIssueManager`. Floating value between 0 and 1 that determines the overall signicance of non-IID issues found in the dataset.
}
Note
For more information, view the source code of: datalab.internal.issue_manager.noniid.NonIIDIssueManager.
Imbalance Issue Parameters#
class_imbalance_kwargs = {
"threshold": # `threshold` argument to constructor of `ClassImbalanceIssueManager`. Non-negative floating value between 0 and 1 indicating the minimum fraction of samples of each class that are present in a dataset without class imbalance.
}
Note
For more information, view the source code of: datalab.internal.issue_manager.imbalance.ClassImbalanceIssueManager.
Underperforming Group Issue Parameters#
underperforming_group_kwargs = {
# Constructor arguments for `UnderperformingGroupIssueManager`
"threshold": # Non-negative floating value between 0 and 1 used for determinining group of points with low confidence.
"metric": # String for the distance metric used for nearest neighbors search if necessary. `metric` argument to constructor of `sklearn.neighbors.NearestNeighbors`.
"k": # Integer representing the number of nearest neighbors for constructing the nearest neighbour graph. `n_neighbors` argument to constructor of `sklearn.neighbors.NearestNeighbors`.
"min_cluster_samples": # Non-negative integer value specifying the minimum number of examples required for a cluster to be considered as the underperforming group. Used in `UnderperformingGroupIssueManager.filter_cluster_ids`.
"clustering_kwargs": # Key-value pairs representing arguments for the constructor of the clustering algorithm class (e.g. `sklearn.cluster.DBSCAN`).
# Argument for the find_issues() method of UnderperformingGroupIssueManager
"cluster_ids": # A 1-D numpy array containing cluster labels for each sample in the dataset. If passed, these cluster labels are used for determining the underperforming group.
}
Note
For more information, view the source code of: datalab.internal.issue_manager.underperforming_group.UnderperformingGroupIssueManager.
For more information on generating cluster_ids for this issue manager, refer to this FAQ Section.
Null Issue Parameters#
null_kwargs = {}
Note
For more information, view the source code of: datalab.internal.issue_manager.null.NullIssueManager.
Data Valuation Issue Parameters#
data_valuation_kwargs = {
"k": # Number of nearest neighbors used to calculate data valuation scores,
"threshold": # Examples with scores below this threshold will be flagged with a data valuation issue
}
Note
For more information, view the source code of: datalab.internal.issue_manager.data_valuation.DataValuationIssueManager.
Image Issue Parameters#
To customize optional parameters for specific image issue types, you can provide a dictionary format corresponding to each image issue. The following codeblock demonstrates how to specify optional parameters for all image issues. However, it’s important to note that providing optional parameters for specific image issues is not mandatory. If no specific parameters are provided, defaults will be used for those issues.
image_issue_types_kwargs = {
"dark": {"threshold": 0.32}, # `threshold` argument for dark issue type. Non-negative floating value between 0 and 1, lower value implies fewer samples will be marked as issue and vice versa.
"light": {"threshold": 0.05}, # `threshold` argument for light issue type. Non-negative floating value between 0 and 1, lower value implies fewer samples will be marked as issue and vice versa.
"blurry": {"threshold": 0.29}, # `threshold` argument for blurry issue type. Non-negative floating value between 0 and 1, lower value implies fewer samples will be marked as issue and vice versa.
"low_information": {"threshold": 0.3}, # `threshold` argument for low_information issue type. Non-negative floating value between 0 and 1, lower value implies fewer samples will be marked as issue and vice versa.
"odd_aspect_ratio": {"threshold": 0.35}, # `threshold` argument for odd_aspect_ratio issue type. Non-negative floating value between 0 and 1, lower value implies fewer samples will be marked as issue and vice versa.
"odd_size": {"threshold": 10.0}, # `threshold` argument for odd_size issue type. Non-negative integer value between starting from 0, unlike other issues, here higher value implies fewer samples will be selected.
}
Note
For more information, view the cleanvision docs.
Cleanlab Studio (Easy Mode)#
Cleanlab Studio is a fully automated platform that can detect the same data issues as this package, as well as many more types of issues, all without you having to do any Machine Learning (or even write any code). Beyond being 100x faster to use and producing more useful results, Cleanlab Studio also provides an intelligent data correction interface for you to quickly fix the issues detected in your dataset (a single data scientist can fix millions of data points thanks to AI suggestions).
Cleanlab Studio offers a powerful AutoML system (with Foundation models) that is useful for more than improving data quality. With a few clicks, you can: find + fix issues in your dataset, identify the best type of ML model and train/tune it, and deploy this model to serve accurate predictions for new data. Also use the same AutoML to auto-label large datasets (a single user can label millions of data points thanks to powerful Foundation models). Try Cleanlab Studio for free!