cleanlab open-source documentation#
cleanlab automatically detects data and label issues in your ML datasets.
Quickstart#
1. Install cleanlab#
pip install cleanlab
To install the package with all optional dependencies:
pip install "cleanlab[all]"
conda install -c cleanlab cleanlab
pip install git+https://github.com/cleanlab/cleanlab.git
To install the package with all optional dependencies:
pip install "git+https://github.com/cleanlab/cleanlab.git#egg=cleanlab[all]"
2. Check your data for all sorts of issues#
cleanlab automatically detects various issues in any dataset that a classifier can be trained on. The cleanlab package works with any ML model by operating on model outputs (predicted class probabilities or feature embeddings) – it doesn’t require that a particular model created those outputs. For any classification dataset, use your trained model to produce pred_probs (predicted class probabilities) and/or feature_embeddings (numeric vector representations of each datapoint). To automatically check your dataset for common real-world issues (like label errors, outliers, near duplicates, IID violations, underperforming groups, …), simply run these few lines of code:
from cleanlab import Datalab
lab = Datalab(data=your_dataset, label_name="column_name_of_labels")
lab.find_issues(features=feature_embeddings, pred_probs=pred_probs)
lab.report() # summarize issues in dataset, how severe they are in each data point, ...
While other data quality tools only catch limited types of data issues based on manually pre-defined validation rules, cleanlab applies automated data-centric AI techniques using your trained ML model to detect many more types of data issues that would otherwise be hard to catch. Don’t dive into ML model improvement without first using AI to help check your data!
3. Handle label errors and train robust models with noisy labels#
Mislabeled data is a particularly concerning issue plaguing real-world datasets. To use a scikit-learn-compatible model for classification with noisy labels, you don’t need to train a model to find label issues – you can pass the untrained model object, data, and labels into CleanLearning.find_label_issues and cleanlab will handle model training for you.
from cleanlab.classification import CleanLearning
# This works with any sklearn-compatible model - just input data + labels and cleanlab will detect label issues ツ
label_issues_info = CleanLearning(clf=sklearn_compatible_model).find_label_issues(data, labels)
CleanLearning also works with models from most standard ML frameworks by wrapping the model for scikit-learn compliance, e.g. pytorch (can use skorch package), tensorflow/keras (can use our KerasWrapperModel), etc.
find_label_issues returns a boolean mask flagging which examples have label issues and a numeric label quality score for each example quantifying our confidence that its label is correct.
Beyond standard classification tasks, cleanlab can also detect mislabeled examples in: multi-label data (e.g. image/document tagging), sequence prediction (e.g. entity recognition), and data labeled by multiple annotators (e.g. crowdsourcing).
Important
Cleanlab performs better if the pred_probs from your model are out-of-sample. Details on how to compute out-of-sample predicted probabilities for your entire dataset are here.
cleanlab’s CleanLearning class trains a more robust version of any existing (scikit-learn compatible) classification model, clf, by fitting it to an automatically filtered version of your dataset with low-quality data removed. It returns a model trained only on the clean data, from which you can get predictions in the same way as your existing classifier.
from sklearn.linear_model import LogisticRegression
from cleanlab.classification import CleanLearning
cl = CleanLearning(clf=LogisticRegression()) # any sklearn-compatible classifier
cl.fit(train_data, labels)
# Estimate the predictions you would have gotten if you trained without mislabeled data
predictions = cl.predict(test_data)
4. Dataset curation: fix dataset-level issues#
cleanlab’s dataset module helps you deal with dataset-level issues – find overlapping classes (classes to merge), rank class-level label quality (classes to keep/delete), and measure overall dataset health (to track dataset quality as you make adjustments).
View all dataset-level issues in one line of code with dataset.health_summary().
from cleanlab.dataset import health_summary
health_summary(labels, pred_probs, class_names=class_names)
5. Improve your data via many other techniques#
Beyond handling label errors, cleanlab supports other data-centric AI capabilities including:
Detecting outliers and out-of-distribution examples in both training and future test data (tutorial)
Analyzing data labeled by multiple annotators to estimate consensus labels and their quality (tutorial)
Active learning with multiple annotators to identify which data is most informative to label or re-label next (tutorial)
If you have questions, check out our FAQ and feel free to ask in Slack!
Contributing#
As cleanlab is an open-source project, we welcome contributions from the community.
Please see our contributing guidelines for more information.
Easy Mode#
While this open-source library finds data issues, its utility depends on you having a good ML model and interface to efficiently fix these issues in your dataset. Providing all these pieces, Cleanlab Studio is a no-code platform to find and fix problems in image/text/tabular datasets. Cleanlab Studio integrates the data quality algorithms from this library on top of cutting-edge AutoML & Foundation models fit to your data, and presents detected issues in a smart data editing interface.
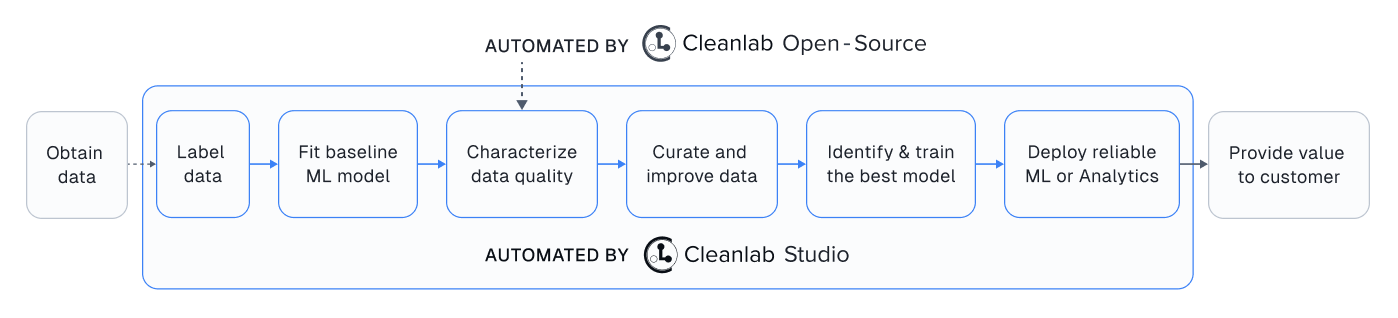
There is no faster way to turn unreliable raw data into reliable models/analytics. Try it for free!
Link to Cleanlab Studio docs: help.cleanlab.ai